[기사공유] 약사국가시험 문제를 활용한 언어모델 (LLM)의 성능평가
안녕하세요. 개발하는 약사 유상준입니다.
이번에 아주 흥미로운 연구를 진행해보았는데요.
바로 챗 GPT에게 약사국가고시를 보게하면 어떤 결과를 가져올까 였습니다.
3.5버전과 4.0버전으로 약사국가고시를 보게하고, 관련 결과를 약국학회에 연구논문을 발표했습니다.
결과가 궁금하시죠? :)
기사 내용 첨부드립니다.
https://www.dailypharm.com/Users/News/NewsView.html?ID=317620
[데일리팜] 챗GPT로 약사국시 풀어보니...응시생 평균 정답률 상회
[데일리팜=정흥준 기자] 챗GPT 두 가지 버전으로 약사국가고시 문제를 풀어보니, 버전에 따라 응시생 평균 정답률을 상회하는 흥미로운 연구 결과가 나왔다. 약학·약료 분야에서 언어모델 LLM(Larg
www.dailypharm.com
챗GPT로 약사국시 풀어보니...응시생 평균 정답률 상회
|
유상준 약사, 국시 활용한 언어모델 성능평가 연구
|
|
GPT 3.5와 4.0 정답률 차이 커...약사법규서 유일하게 과락
|
[데일리팜=정흥준 기자] 챗GPT 두 가지 버전으로 약사국가고시 문제를 풀어보니, 버전에 따라 응시생 평균 정답률을 상회하는 흥미로운 연구 결과가 나왔다.
약학·약료 분야에서 언어모델 LLM(Large Language Model)의 성능 차이가 극명하게 나타난 것이다. 앞으로도 약료 분야 LLM의 성능을 보완하는 기준점이 될 수 있을 것으로 보고 있다.
유상준 약사(디어라운드 CTO)는 최근 약국학회에 ‘약사국가시험 문제를 활용한 언어모델 (LLM)의 성능평가를 주제로 연구논문을 발표했다.
미국과 일본 등 해외에서는 유사한 선행 연구들이 있지만 한국에서는 생소한 연구다. 약사자격을 검증하는 시험을 챗GPT 3.5와 4.0을 이용해 풀도록 하고 성능을 비교 분석했다.
시험 문제는 올해 치러진 제75회 약사국가시험 중 비공개 문제를 제외한 모든 문항을 가지고 진행됐다.
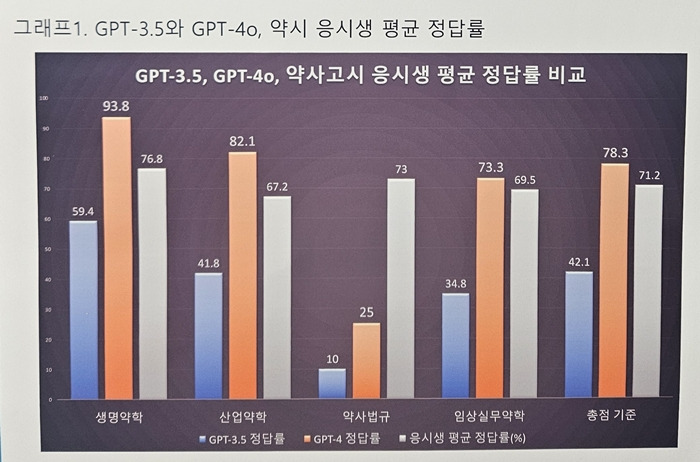
▲ GPT 4, 응시생, GPT 3.5 순으로 높은 정답률을 보였다. 유일하게 약사법규에서 응시생이 가장 높은 정답률을 기록했다.
챗GPT 두 버전의 정답률 차이는 컸다. GPT 3.5가 생명약학에서 59.4%의 정답률은 보인 반면 4.0은 93.8%의 정답률을 보였다. 산업약학에서는 41.5%과 82.1%, 임상실무약학1은 33.8%과 63.6%, 임상실무약학2는 36.2%와 86.2%를 기록했다. 약사법규도 3.5는 10%, 4.0은 25%의 정답률을 보였다.
전문 용어와 임상적 지식이 필요한 복잡한 임상 문제를 풀어야 하는 ’임상실무약학2‘에서 특히 성능차이가 드러났다.
GPT 4.0은 약사법규를 제외한 모든 과목에서 실제 응시생 평균 정답률을 상회했다. GPT 3.5는 모든 과목에서 응시생 정답률을 하회했다.
약사법 특성상 어려운 용어, 달라지는 법 개정 등을 제대로 반영하지 못하는 것으로 분석했다. 유 약사는 이번 연구로 약료 LLM의 성능을 확인하는 기준을 마련하고, 약사법규 분야에서 성능 개선이 필요하다는 점을 파악했다.
유 약사는 “외국에는 국가고시 문제를 가지고 이뤄지는 언어모델 연구들이 많은 반면 국내에서는 이뤄지지 않아 연구를 진행해봤다”면서 “일단 두 가지 모델이 성능에 유의미한 차이점을 보였다는 점이 흥미롭다. 좋은 성능을 보여준 모델의 신뢰도를 확인할 수 있었다”고 설명했다.
이어 유 약사는 “새로운 모델을 만들 때 기능적 신뢰도를 평가하는 기준으로도 활용할 수 있다. GPT가 응시생 정답률을 상회한다고 해서 인력을 대체할 수 있다는 뜻은 아니다. 약사가 언어모델을 평가하며 관리해야 하는 것이고, 활용 후 판단에 대한 책임 또한 약사에게 있다”고 강조했다.